Notes on Amazon Aurora (2017, 2018)
Sun Mar 07 2021tags: programming computer science self study notes public 6.824 MIT distributed systems
Introduction
I read the following two papers as part of my self-study of 6.824 with NUS SoC folks. It may or may not be part of my goal to finish a Stanford CS degree in a year.
The two papers I read are
- [Verbitski et al. (2017). Amazon Aurora--Design Considerations for High Throughput Cloud-Native Relational Databases](https://files.lieu.gg/docs/Verbitski et al. (2017). Amazon Aurora--Design Considerations for High Throughput Cloud-Native Relational Databases.pdf) and
- [Verbitski et al. (2018). Amazon Aurora--On Avoiding Distributed Consensus for IOs, Commits, and Membership Changes](https://files.lieu.gg/docs/Verbitski et al. (2018). Amazon Aurora--On Avoiding Distributed Consensus for IOs, Commits, and Membership Changes.pdf)
While the papers were great, they were not detailed enough for my taste. They kind of gloss over the details of how the system is implemented, and they don't really give a step-by-step breakdown of how reads and writes are done and what state is being kept/sent/propagated.
So here I want to first give a big-picture view: what Aurora does and why it's important, then a step-by-step breakdown of how writes, reads, and commits are performed in Amazon Aurora.
Here I assume that you have already read the Aurora paper and I'm not going to mention things that can be easily looked up in the paper. I will instead try to explain what I believe to be their motivations for building this system, the key contributions of the papers and elaborate on some things I believe are underspecified.
Glossary
- AZ: availability zone
- OLTP: Online transaction processing
- PG: protection group. An Aurora storage service is divided into six protection groups that replicate the data six-way.
- MVCC: Multi-view concurrency control. This ensures that read replicas always read the freshest possible version of the databases.
- MTR: Mini-transaction. Each database transaction in MySQL is a sequence of ordered mini-transaction (MTRs) that are performed atomically. A mini-transaction is made up of multiple log entries.
- VCL: Volume Complete LSN. This is the highest LSN on the storage node for which all previous logs are available.
- CPL: Consistency Point LSNs. This is a point where it's safe to commit, and the point that will be reached after recovering from a crash.
- VDL: Volume Durable LSN. This is the highest CPL that is smaller than the VCL.
The big picture
Amazon is trying to make its normal SQL database more fault tolerant. The easiest way to make databases fault tolerant is to have three replicated databases, and have a quorum of 2 for all writes/reads. But this isn't good enough for Amazon's purposes: Amazon wants fault tolerance at the level of one availability zone (AZ) failure + one additional node failure. (An availability zone is a geographic region: the idea is that if say the entire US blacks out, you can use the Asia and South America replicas.) With three nodes in different AZs, you can't reach quorum if two nodes fail. Hence we need to use six replicas.
But if we use six replicas, the problem that results is that i) databases are chatty and ii) write requests in traditional DB systems are synchronous and the bottleneck quickly becomes network I/O. In a traditional database system this would mean large latencies in write requests.
So the key question Aurora aims to answer is: how can we get greater fault-tolerance while keeping read/write latencies low? Aurora aims to reduce these latencies while giving us the guarantees of a traditional relational DB.
What Aurora is and what makes it special
Amazon Aurora is a CP system. It gives you the guarantees of a relational DB, while being much quicker. But it's not available, because if there's a network partition, it can't reach quorum (more on this later). This is different from Amazon's DynamoDB, which is AP and eventually consistent.
How does Aurora do it? In my opinion, Aurora makes two key contributions: separating the database layer from the storage layer, and making the log the database. Aurora separates the database layer from the storage layer, which allows writes to be done asynchronously without having to wait for the data to be replicated to disk. The database layer applies writes to its own buffer cache after it receives confirmation from the storage layer. This allows the database to service client requests (with its cache) while previous write requests are written and replicated asynchronously on the storage layer. Pages are (again, asynchronously) generated by the storage layer and surfaced when needed in response to a read request. This solves the latency issue.
Another way they reduce latency is by decreasing the amount of data that needs to be replicated by sending only the write-ahead logs: "the log is the database." They use a strictly increasing log number called the Log Sequence Number (LSN) to make sure logs are consistently replicated across the six replicas.
In more detail
There's one primary read-write instance (leader) and multiple replica read-only database instances. There's only one storage volume, replicated six ways (each replica is called a PG, or "protection group") in three different AZsf.
Write requests
What exactly happens when Aurora needs to service a write request?
- The primary replica is the main source of truth. It keeps some important state. The most important number is the Log Sequence Number (LSN). It also keeps volume durable log (VDL) records and current epoch number.
- The primary replica receives a write request, which is a database transaction.
- The database-level transaction is broken up into multiple mini-transactions that are ordered and must be performed automically.
- Each mini-transaction is itself composed of multiple contiguous log records. Because the primary replica is the main source of truth, it knows exactly what LSNs it needs to issue for each log record: this is important because of failure recovery and truncation range.
- These log records are sent asynchronously to the storage service. Each storage node persists the log records to an update queue, and responds with an acknowledgement, along with the Segment Complete LSN (SCL). All of this is asynchronous.
- When the primary replica receives a quorum acknowledgement from 4 out of 6 storage nodes, that write is considered done. When the replica observes SCL advance at four of six members, it locally advances the "Protection Group Complete LSN" (PGCL), which is the point at which the protection group has made all writes durable.
- If an MTR is complete (the quorum SCL > the LSN of the last log entry in the MTR), The primary instance may ship the MTR chunks and the new VDL to its read replicas, which applies them sequentially to generate its own cached version of the pages.
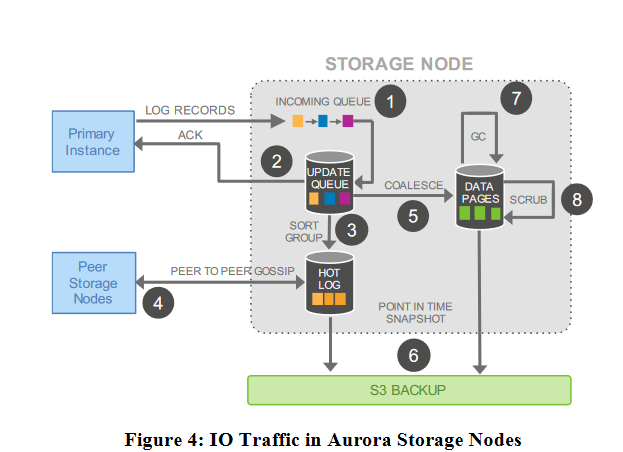
The database instance acquires latches for each data block, allocates a batch of contiguously ordered LSNs,generates the log records, issues a write, shards then into writebuffers for each protection group associated with the blocks, andwrites them to the various storage nodes for the segments in theprotection group. We use an additional consistency point, the Vol-ume Durable LSN (VDL), to represent the last LSN below VCLrepresenting an MTR completion.
Replicas do not have the benefit of the latching used at thewriter instance to prevent read requests from seeing non-atomic structural updates. To create equivalent ordering, we ensure that log records are only shipped from the writer instance in MTR chunks. At the replica, they must be applied in LSN order, applied only if above the VDL in the writer as seen in the replica, and applied atomically in MTR chunks to the subset of blocks in the cache. Read requests are made relative to VDL points to avoid seeing structurally inconsistent data
Read requests
Aurora cleverly avoids quorum reads (that is, querying all six PGs, and waiting for the quorum of 3). Why would you ever need a quorum read? If you don't do a quorum read you run the risk of querying a node that has stale data: e.g. you read from a node that's one of the two nodes that wasn't included in the write quorum. The primary replica never needs to do a quorum read, obviously, because it knows exactly which PGs have the latest writes.
But how do the read replicas avoid quorum reads? The read replicas are sent the VDL by the primary replica, and I'm guessing if they query a node whose CPL (Consistency Point LSN) is lower than the VDL (the VDL is the highest CPL that is smaller than equal to VCL), they retry with another node?
When reading a page from disk, the database establishes a read-point, representing a VDL at the time the request was issued. The database can then select a storage node that is complete with respect to the read point, knowing that it will therefore receive an up to date version
Commit requests
Recovery
Epoch numbers
The idea of "epochs" are very similar to the term value in Raft. Epochs are used to invalidate stale requests after a crash in the database instance.
How a database works
Traditional relational databases organize data in pages, and as pages are modified, they must be periodically flushed to disk. For resilience against failures and maintenance of ACID semantics, page modifications are also recorded in redo log records, which are written to disk in a continuous stream. While this architecture provides the basic functionality needed to support a relational database management system, it's rife with inefficiencies. For example, a single logical database write turns into multiple (up to five) physical disk writes, resulting in performance problems.
I don't really understand how databases work, and why they need to write so many things.
Thankfully the 6.824 lecture notes on Aurora has a very helpful explanation:
Paper assumes you know how DB works, how it uses storage.
here's an overview of a generic transactional DB
single machine
example bank transaction -- transfer $10 from x's account to y's account
x = x + 10
y = y - 10
locks x and y, released after commit finishes
data in b-tree on disk
cached data pages
DB server modifies only cached data pages as transaction runs
and appends update info to WAL (Write-Ahead Log)
the paper's "redo log" == MySQL's INNODB transaction log.
log entries:
LSID TID key old new
101 7 x 500 510 (generated by x = x + 10)
102 7 y 750 740 (generated by y = y - 10)
103 7 commit (transaction finished)
commit once WAL safe on disk
release locks on x and y
reply to client
later write modified data pages from cache to disk
to free log space, allow cache eviction
crucial to performance to delay -- write absorbtion, since pages are big
crash recovery
replay "new" values for all committed xactions in log (redo)
replay "old" values for uncommitted xactions in log (undo)
Traditional databases have to write so many things over the network because there is no compute in your storage: the storage is dumb. It can't generate the pages from the redo log.
What is a write-ahead log?
From Wikipedia:
In computer science, write-ahead logging (WAL) is a family of techniques for providing atomicity and durability (two of the ACID properties) in database systems. The changes are first recorded in the log, which must be written to stable storage, before the changes are written to the database.
In Aurora the write replica sends a write request to the storage service, which writes it to an update queue (this is the write ahead log!). Only this step is synchronous, and responsible for the write latency.
But once it's written to the four update queues (you need four nodes for quorum), the database service can be assured that this write will succeed, and can return the client a result. The results can then be slowly persisted to disk asynchronously by the storage service, freeing up the database service to service more requests.
What's a data page?
Databases store data in terms of pages, pages tend to be 4KB. In general, each row is in a page (barring very large rows) and is written to disk.
If the Aurora DB doesn't write a lot of this stuff to disk, why do these old DBs need to write to disk? What is the tradeoff that we're making here?
The key tradeoff is that your storage now needs compute. Your storage has to do the job of taking the log and building pages from it, where previously this was done by the database instance.
FAQ
Why might read replicas get stale reads?
The redo log seen by a read replica does not carry the stateneeded to establish SCL, PGCL, VCL, or VDL consistency points.Nor is the read replica in the communication path between thewriter and storage nodes to establish this state on its own. Notethat VDL advances based on acknowledgements from storage nodes,not redo issuance from the writer. The writer instance sends VDL update control records as part of its replication stream. Althoughthe active transaction list can be reconstructed at the replica us-ing redo records and VDL advancement, for efficiency reasons weship commit notifications and maintain transaction commit history.Read views at the replica are built based on these VDL points andtransaction commit history
VDL on the replica may lag the writer -- hence read replicas may get stale reads. How? This may happen if the primary instance has already written and committed and advanced the VDL locally but hasn't sent "VDL update control records" yet as part of its replication stream to the secondary replica.
Why don't database instances have to flush dirty pages?
What is the yellow arrow in Figure 2 point to Amazon S3? What is a binary (statement) log?
[TODO] not sure..
How does the storage service scale out I/Os in an "embarassingly parallel fashion"?
Firstly, the storage nodes are divided into independent storage segments of 10GB each, this means that nodes can spin up and down very quickly and segments can be repaired in 10 seconds over a 10 Gbps connection. So this scales very well. What I think they mean by "embarassingly parallel" is that each storage node (or PG, I suppose) is independent, and there's no additional bookkeeping to keep each node in sync. Hence the database isntance can send to all these PGs simultaneously and all of them can process the writes in parallel.
Why don't you need a quorum read? How does Aurora ensure that it gets the latest version of the read without a quorum read?
See the top section on this
What is a read replica?
Section 3.2 of the 2018 paper ("Scaling Reads using Read Replicas"):
Many database systems scale reads by replicating updates froma writer instance to a set of read replica instances. Typically, thisinvolves transporting either logical statement updates or physicalredo log records from the writer to the readers. Replication is donesynchronously if the replicas are intended as failover targets with-out data loss and asynchronously if replica lag or data loss duringfailover is acceptable
Aurora supports logical replication to communicate with non-Aurora systems and in cases where the application does not wantphysical consistency – for example, when schemas differ. Internally,within an Aurora cluster, we use physical replication. Aurora readreplicas attach to the same storage volume as the writer instance.They receive a physical redo log stream from the writer instanceand use this to update only data blocks present in their local caches.Redo records for uncached blocks can be discarded, as they can beread from the shared storage volume
This approach allows Aurora customers to quickly set up and teardown replicas in response to sharp demand spikes, since durablestate is shared. Adding replicas does not change availability ordurability characteristics, since durable state is independent fromthe number of instances accessing that state. There is little latencyadded to the write path on the writer instance since replicationis asynchronous. Since we only update cached data blocks on thereplicas, most resources on the replica remain available for read re-quests. And most importantly, if a commit has been marked durableand acknowledged to the client, there is no data loss when a replica
What happens when a storage node fails after acknowledging the primary instance (e.g. written to Update Queue), but before it persists that data to disk?
This doesn't happen, because the update queue is persisted to disk.
What's the difference between a write and a commit?
A write is a single write operation, while
a commit is committing an entire transaction,
which can contain multiple write and read transactions.
Committing a transaction means making it atomic:
saying that ALL the operations in that transaction have
passed (or failed).
What are the differences between Aurora and Raft?
Obviously, Raft is a consensus algorithm, while Aurora is a database deployment. It's more accurate to ask the question: how does Aurora manage to maintain a consistent state and how does it compare to the way that Raft does it?
At first glance they seem quite similar. There is one leader which is the source of truth. This leader writes to a log, which is then applied to get the state. Aurora's "epoch" is a monotonically increasing value, much like the "term" in Raft: it's provided as part of every read or write to a storage node, and storage nodes will not accept requests at stale volume epochs.
The key assumption Aurora can make is that there is a common shared state. In Raft we can't assume that we have e.g. the provably correct term number, the provably correct leader, even the provably correct log. and what not. So there's a difficult problem of consensus; we need to agree on a leader, agree on the term, without a single source of truth. In Aurora there's no need for consensus: you literally just read the log from the storage service, and read the VDL/epoch/etc. directly from the metadata store.
In this sense, Aurora isn't really a distributed system at all! We always know the VDL, largest LSN, and epoch, because these are all persisted in the metadata store. And once we have quorum from the four out of six storage nodes, we're guaranteed that we will always know the correct VCL. The only distributed bit is the storage service, but again there's no issue with consensus because each storage service HAS to append its logs as long as the epoch number is valid. The storage service has to query the storage metadata service before servicing any read or write request (page 792 of 2018 paper). (what happens when the storage service receives a stale volume epoch though?)
What are the similarities and differences between Aurora and Memcache?
Do replicas apply log records ABOVE or BELOW the VDL?
2017 paper section 4.2.4, "Replicas" says:
The replica obeys the following two important rules while applying log records: (a) the only log records that will be applied are those whose LSN is less than or equal to the VDL, and (b) the log records that are part of a single mini-transaction are applied atomically in the replica's cache to ensure that the replica sees a consistent view of all database objects.
2018 paper section 3.3, "Structural Consistency in Aurora Replicas" says:
To create equivalent ordering, we ensure that log records are only shipped from the writer instance in MTR chunks. At the replica, they must be applied in LSN order, applied only if above the VDL in the writer as seen in the replica, and applied atomically in MTR chunks to the subset of blocks in the cache. Read requests are made relative to VDL points to avoid seeing structurally inconsistent data.
So is it "less than or equal to", or "above" the VDL??
EDIT: Thanks Zongran:
So the 2017 statement means that you only apply the redo logs whose LSN is below VDL as they are considered durable by quorum; 2018’s statement has this context that the read instance’s view of the write’s VDL is lagging, and hence you only need to make up using those redo logs from write instance whose LSN is higher than your current view of the writer’s VDL
Bibliography
- https://blog.acolyer.org/2019/03/25/amazon-aurora-design-considerations-for-high-throughput-cloud-native-relational-databases/
- https://www.allthingsdistributed.com/2019/03/Amazon-Aurora-design-cloud-native-relational-database.html
- MIT Lecture Notes on Aurora
- MIT Aurora FAQ